llm-eval-simple a simple way to evaluate LLM for your use case

Every week a new AI LLM is released, but will it really change your life? With llm-eval-simple, you can easily test new LLMs for your use case and have an objective metric.
Which is the best LLM?
Speed, knowledge, context size, efficacy, creativity, instruction following, censorship—it depends on your AI agent or your use case. Public benchmarks like Livebench are useful, but in the "real world," factors such as RAM consumption, speed, quantization, parameters, system prompt, etc., can make a difference. Therefore, it is always better to test on your specific use case.
llm-eval-simple is a very simple way to test your OpenAI-compatible API with many AI models and prompts.
Directory Structure
prompts/- Place one file per prompt here.answers- Place one file per expected answer here..env- Here, you specify your OpenAI-compatible endpoint, the models you want to test, and the model used as the "evaluator."
And then the magic begins:
uv run main.py --actions answer,evaluate,render --pattern "prompts/REASON*"
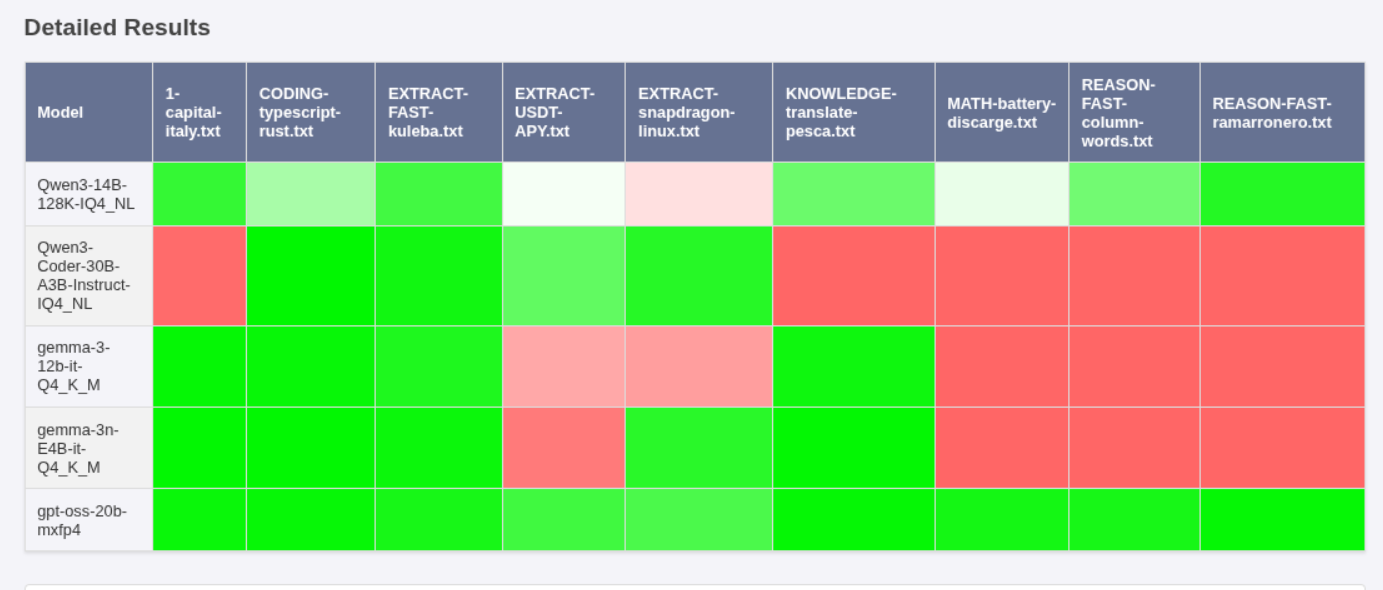
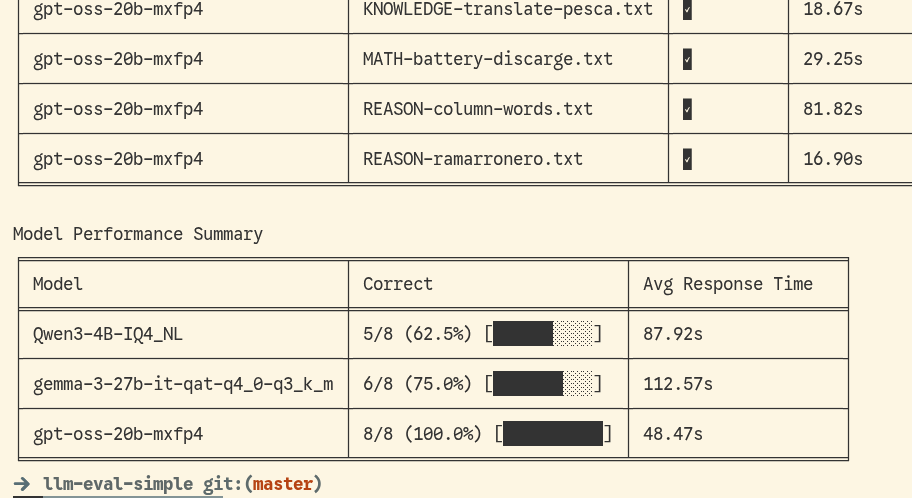
You can easily generate the report with correctness and speed per model with intermediate files, so you can back up the report or re-execute it with a different evaluator without re-asking the generated questions. You can also generate the report for only a subset of your prompts.
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gemma-3-27b-it-qat-q4_0-q3_k_m │ REASON-column-words.txt │ 𐄂 │ 14.53s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gemma-3-27b-it-qat-q4_0-q3_k_m │ REASON-ramarronero.txt │ 𐄂 │ 5.85s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ 1-capital-italy.txt │ 🮱 │ 26.83s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ BIGCONTEXT-kuleba.txt │ 🮱 │ 48.03s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ CODING-typescript-rust.txt │ 🮱 │ 33.07s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ EXTRACT-USDT-APY.txt │ 🮱 │ 133.22s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ KNOWLEDGE-translate-pesca.txt │ 🮱 │ 18.67s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ MATH-battery-discarge.txt │ 🮱 │ 29.25s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ REASON-column-words.txt │ 🮱 │ 81.82s │
├────────────────────────────────┼───────────────────────────────┼───────────┼─────────────────┤
│ gpt-oss-20b-mxfp4 │ REASON-ramarronero.txt │ 🮱 │ 16.90s │
╘════════════════════════════════╧═══════════════════════════════╧═══════════╧═════════════════╛
Model Performance Summary
╒════════════════════════════════╤═══════════════════════════╤═════════════════════╕
│ Model │ Correct │ Avg Response Time │
╞════════════════════════════════╪═══════════════════════════╪═════════════════════╡
│ Qwen3-4B-IQ4_NL │ 5/8 (62.5%) [██████░░░░] │ 87.92s │
├────────────────────────────────┼───────────────────────────┼─────────────────────┤
│ gemma-3-27b-it-qat-q4_0-q3_k_m │ 6/8 (75.0%) [███████░░░] │ 112.57s │
├────────────────────────────────┼───────────────────────────┼─────────────────────┤
│ gpt-oss-20b-mxfp4 │ 8/8 (100.0%) [██████████] │ 48.47s │
╘════════════════════════════════╧═══════════════════════════╧═════════════════════╛