Are Local LLMs good enough for Vibe Coding? Gemma4-26B-A4B vs Qwen3.5-35B-A3B

Following some "real world" agentic benchmarks with OpenCode (aka ClaudeCode opensource alternative) and Pi-Coding-Agent (aka the OpenClaw core harness).
What to test?
I created a small Bun/Svelte application an I ask to the LLM to do some changes that require custom skill usage and custom CLI tool usage.
NB: It's a basic coding agentic scenario, you could extend it to more complex scenario and bigger context if you have the proper hardware and RAM.
Pi with models in No thinking mode (because it's faster in non-math or complex scenarios
OpenCode with Gemma4-26B-A4B vs Qwen3.5-35B-A3B with reasoning/thinking active.
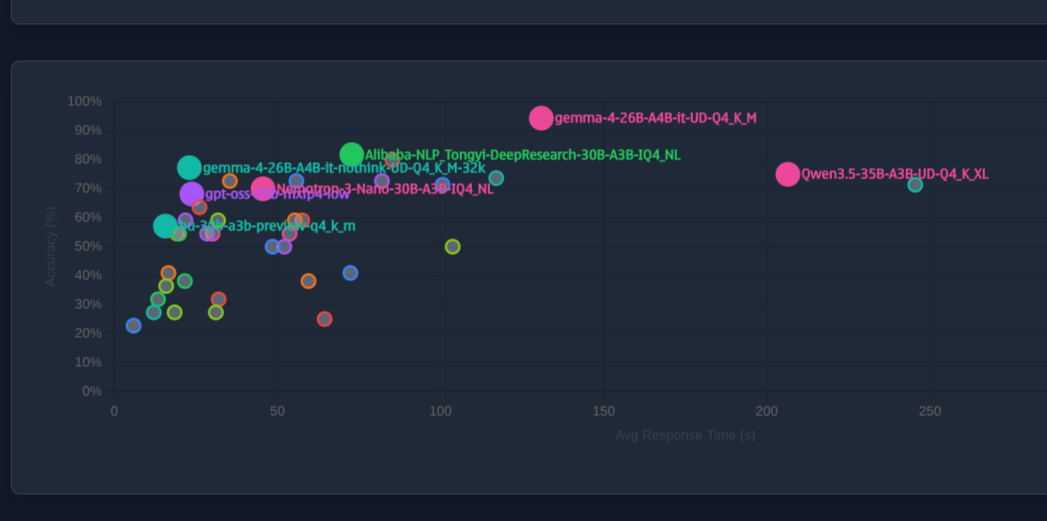
Who is the winner?
Honestly I don't have an answer:
- Pi Coding Agent has usually a small context footprint by default but without guidelines it can make mistakes in tool usage.
- OpenCode has a more rich startup context, so it is slower to start but it had less issues with tool calling
- Qwen3.5-35B-A3B probably it is a little better in coding/agentic tasks, but for single prompt Gemma4-26B-A4B has the best tradeoff quality per speed.
Do you have better local models or harness, discuss on Hacker News https://news.ycombinator.com/item?id=47677086