Accuracy vs Speed in Local LLMs: Finding Your Sweet Spot


Local LLMs evolve fast. Balancing accuracy and performance is not one-size-fits-all; your best fit depends on hardware, use case, and how much context you need for your workflows.
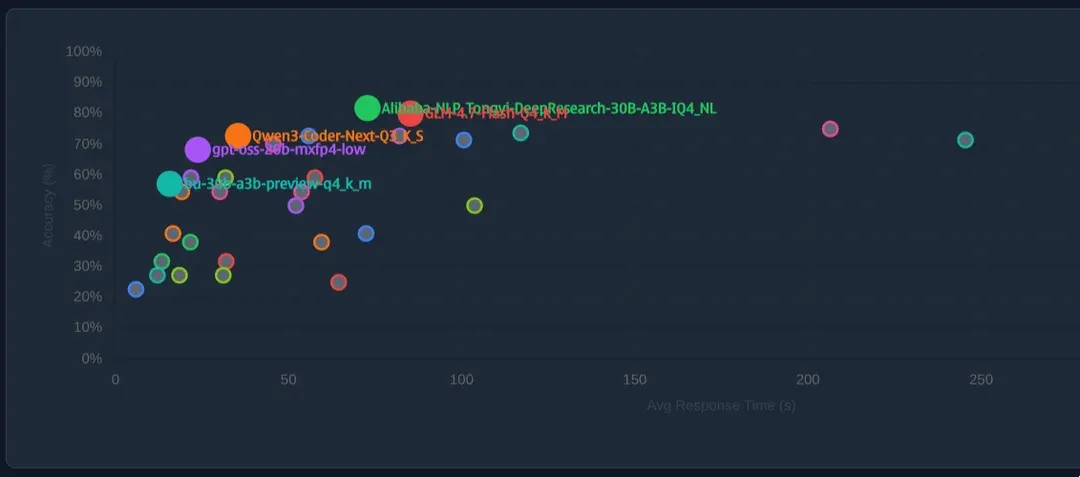
Accuracy vs speed chart created on my personal coding/agentic benchmark with llm-eval-simple
The Core Trade-off
- Highly accurate models often demand more VRAM and compute.
- Faster models frequently trade some reasoning depth or long-context handling.
- Your ideal choice depends on: hardware (GPU RAM, system RAM, CPU), task type (coding, research, scraping, general assistant), and required context window.
My Sweet Spots
Top 1: Best Accuracy
- Model focus: Tongyi DeepResearch 30B-A3B (30B total, ~3B activated per token) with high-precision quantization.
- Why it helps: Strong agentic reasoning and deep information-seeking capability; IQ4_NL-style quantization reduces memory footprint while preserving quality.
- Key links:
- Base Tongyi DeepResearch page: https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
- GGUF/Unsloth-style variants (examples): https://huggingface.co/bartowski/Alibaba-NLP_Tongyi-DeepResearch-30B-A3B-GGUF
Top 2: Best Accuracy/Speed Trade-off
- Model focus: Qwen3-Coder-Next family (80B MoE with only ~3B active per token; 256K context in some configurations).
- Why it helps: Substantial coding performance with efficient quantization; practical on mid-range GPUs with Unsloth Dynamic 2.0 GGUFs.
- Key links:
- Unsloth Qwen3-Coder-Next GGUF: https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
- Example Q3_K_S GGUF: https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF/blob/main/Qwen3-Coder-Next-Q3_K_S.gguf
- Documentation / guides (Unsloth): https://unsloth.ai/docs/models/qwen3-coder-next
Top 3: Best for Scraping/Fast Tasks
- Model focus: Nemotron-3-Nano-30B-A3B-GGUF (and IQ4_NL variant).
- Why it helps: Fast inference with solid reasoning for quick data gathering tasks and prompt-instrumentation work.
- Key links:
- Nemotron-3-Nano-30B-A3B-GGUF: https://huggingface.co/unsloth/Nemotron-3-Nano-30B-A3B-GGUF
- IQ4_NL GGUF variant: https://huggingface.co/unsloth/Nemotron-3-Nano-30B-A3B-GGUF/blob/a2c9964e47d625c732f6f0e50741021127eb5b3d/Nemotron-3-Nano-30B-A3B-IQ4_NL.gguf
Honorable Mentions
- THUDM/GLM-4.7-Flash-Q4_K_M: Very strong accuracy, but generally slower than the top contenders.
- Qwen/Qwen3-Coder-Next-Q3_K_S: Good trade-off, but performance can vary with hardware and interface.
- See UnsLOTH GGUFs for the best local experience: https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
Opencode Notes
For OpenCode workloads with long contexts the situation is different, gpt-oss-20b and Nvidia Nemotron 30B A3B are the only options or maybe other models need some tweaks.
Community Signals
- Local/offline coding workflows favor models with coherent reasoning and fewer “read-file loops.”
- Community discussions (Reddit and model hubs) highlight the importance of optimized quantization, MoE behavior, and proper llama.cpp LLAMA_CURL/LLAMA_CUDA configurations for best speed and stability.
- Unsloth’s own docs and GGUF releases emphasize 4-bit quantization with options like QAT for accuracy recovery, which can be valuable if you need higher fidelity at lower bitwidths.
The Bottom Line
There isn’t a single perfect model. The sweet spot is a function of hardware and use case. For local coding and long-context workflows on consumer hardware, the strongest starting points are:
- Tongyi DeepResearch 30B-A3B GGUFs (high accuracy with efficient quantization)
- Qwen3-Coder-Next GGUFs (Unsloth Dynamic 2.0)
- Nemotron-3-Nano-30B-A3B-GGUF (fast, good for quick tasks)
What are your tradeoffs accuracy vs speed with local LLM ? Leave a comment on HN.