Vibe Coding Myths vs. Reality: Why AI Isn’t a Bubble. Insights from llm-eval-simple


Vibe Coding Myths and Reality: AI Isn't a Bubble
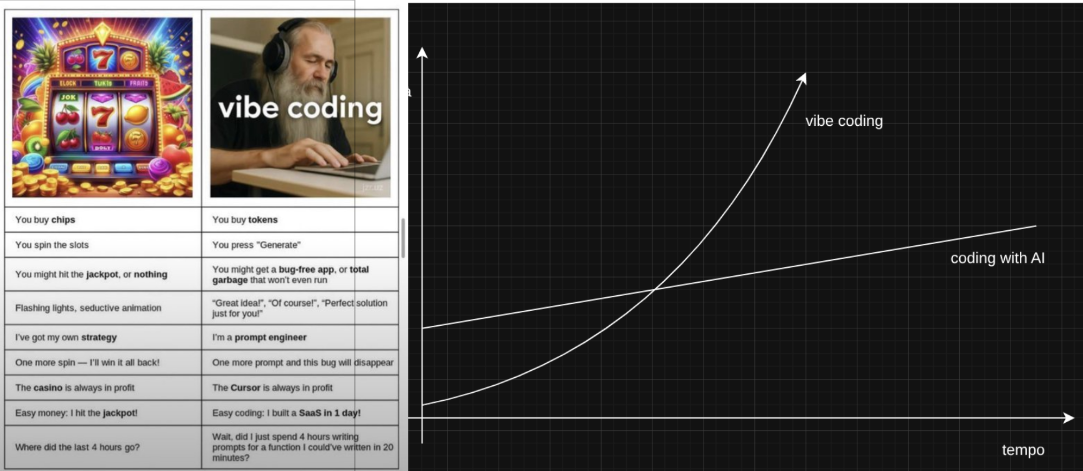
AI could be a financial bubble but it isn't a technical bubble. With basic knowledge you can build and optimize almost without effort.
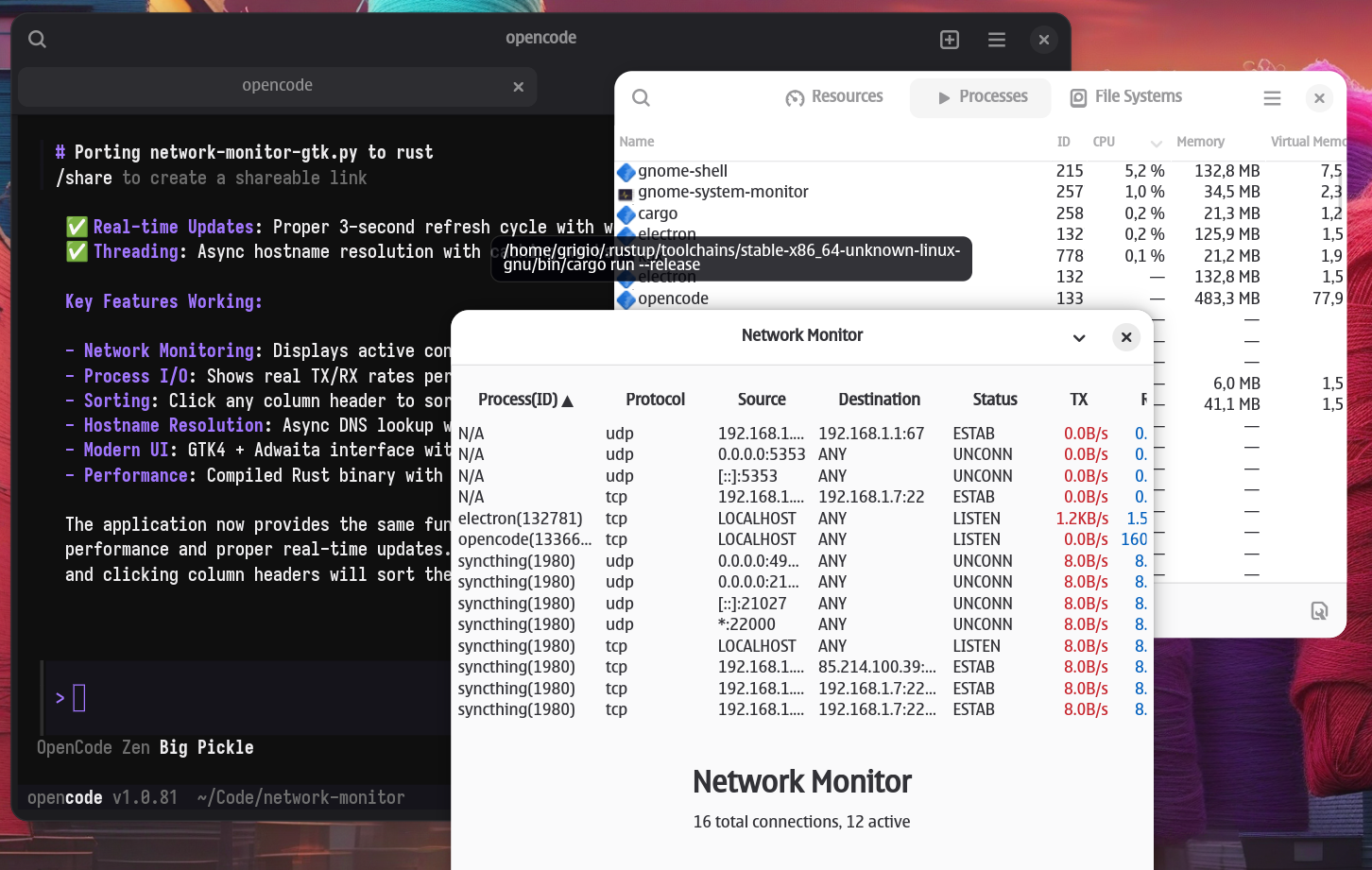
With a bit of prompt engineering and an hour, I built Network Monitor - a tool to monitor anomalous internet connections for Linux. I first built it in Python, then rewrote it in Rust and saved 50% of RAM usage.
What's Worth Learning When AI "Does Everything"?
Technical terms aren't for showing off - they're for being more precise when instructing and optimizing AI.
In my case:
- "Asynchronous" instead of "slow"
- "Table header" instead of "title"
The more precise your technical vocabulary, the better you can guide AI toward optimal solutions.
Local LLMs for Coding: Are We Ready?
In my experimentation, I've used opencode + "Big Pickle" model (which should be GLM4.6), and it's amazing.
According to the Gosu benchmark, Claude Code currently appears to be the best option, but alternatives aren't far behind. Beyond a certain complexity level, it's the human developer's knowledge that makes the difference.
Recent comparisons show that tools like Cursor, Claude Code, and opencode each have their strengths:
- Claude Code: Excels in complex problem-solving with large context
- Cursor: Great for integrated development workflows
- Opencode: Extremely fast with models like Grok Code Fast 1
Are Local LLMs Good Enough? Check with llm-eval-simple
Small local LLMs are fantastic! Even with less knowledge, when used in an agentic way they can learn from context - which is basically what humans do. A person doesn't know everything but knows where to find the answer or learn the tool to find it.
Online frontier models will always be better because they don't have space or energy constraints, but local LLMs can be specialized and focused for your problem.
Small LLMs can already be useful for file-level coding. For project-level work, you need bigger LLMs with more context space. You can do it, but you'll need to invest in expensive hardware.
However, big frontier LLMs will always have outdated data, so they also need to fetch internet for updated data - just like small LLMs.
My Current Top LLMs for Modest Hardware:
- gpt-oss-20b-mxfp4 (generalist, good tradeoff between speed and correctness in my HW)
- Alibaba-NLP_Tongyi-DeepResearch-30B-A3B for coding (but it's slow)
- Mistral-Nemo-Instruct-2407-Q4_K_M for fast, structured translations
Local LLMs vs Frontier LLMs: Not Direct Competitors
Local LLMs and frontier LLMs aren't direct competitors - they have different scales, like a home kitchen and a fast food restaurant.
Local LLMs advantages:
- Privacy
- Offline functionality
- Determinism
- More tweakable
Remote LLMs advantages:
- More powerful
- But more censored
- You'll never know what happens to your personal data
The Reality of AI-Assisted Development
The key insight is that AI tools are force multipliers, not replacements. Your technical knowledge determines how effectively you can:
- Guide the AI with precise terminology
- Validate the output for correctness and efficiency
- Optimize the solution based on your understanding of the domain
My Network Monitor project demonstrates this perfectly: the AI helped me build it quickly, but my knowledge of Rust, GTK4, and system programming allowed me to optimize it significantly when moving from Python to Rust.
Testing Local LLMs for Your Use Case
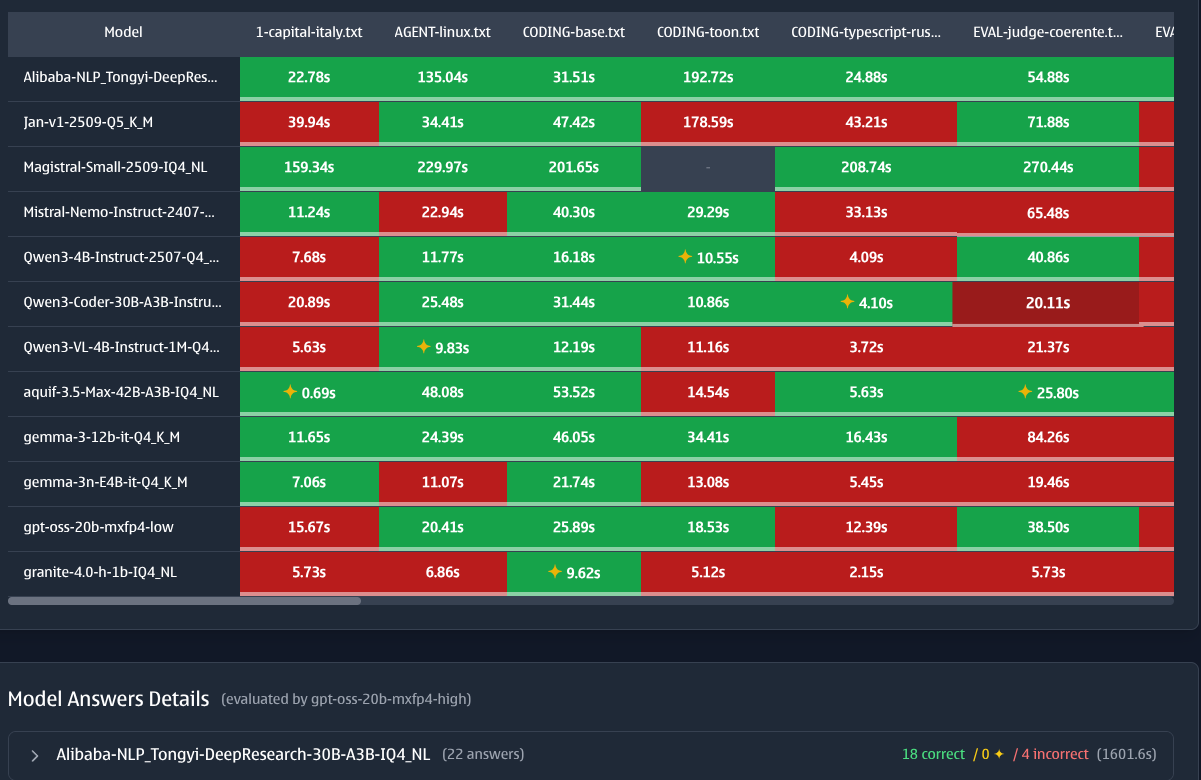
llm-eval-simple helps you test local LLMs for your specific use case. Don't rely on generic benchmarks - test with your actual workflows and requirements.
The future of development isn't AI replacing developers, but developers who effectively leverage AI replacing those who don't.