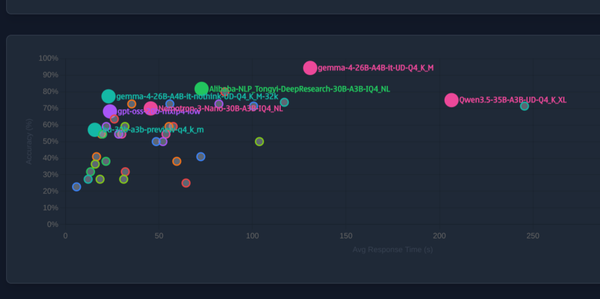
Both models are Mixture of Experts (MoE) architectures. Qwen3.6 35B A3B outperforms Gemma4 26B A4B on coding/agent tasks significantly, while Gemma4 has advantages in multimodal capabilities and smaller file size.
Model Specifications
Specification
Gemma4 26B A4B
Qwen3.6 35B A3B
Architecture
MoE (128 experts)
MoE (8 experts)
Total